Today I learned something very handy: how to encode subjective beliefs into a Bayesian prior when you only have information on the quantiles.
I hadn't realized it, but this is super useful: nobody can give you a fully described distribution, but everyone can give you a range of likelihoods, and talking with people is one (important) way to inform your prior. For example, a person might say, "well, I'm pretty sure most people love pizza between 50 and 70 happiness points", or somesuch. Previously, I wouldn't have known what to do with that information. How do I fit a probability density function around that pizza love? When I have only two vague points?
In the past, whenever I wanted to set a prior, I would do one of the following:
- Set an uninformative one, such as the uniform distribution. This assumes that everyone loves pizza an equal amount.
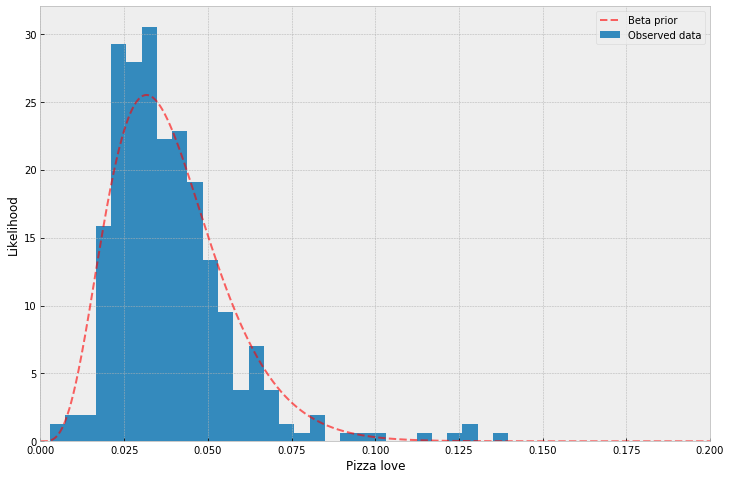
- Set a prior based on some historical data, e.g. fitting a beta distribution to some observed historical data and pray that nothing has changed since that data was collected/it doesn't bias my updating too hard. I feel like this is Sullied Bayes, though, since we're not technically supposed to be using data in the "setting the prior" stage. But, well, okay, I've done it. I do it.
- Build a model in PyMC3, hand-picking some distributions and hand-picking their parameters, based on some subjective and vague understanding of the world. E.g. "I know that I love an average pizza at about 70 points and I guess I'll use a Normal distribution around that mean with a low variance of, uh, 5 points, because - honestly - pizza is never that bad, right?" What nonsense, I know.
But today I was hanging out on StatsOverflow and came across a very useful idea: how to incorporate quantiles information into a prior. YES. What a useful thing.
Here's how it works in practice:
SCENE 1. The RENAISSANCE BOTTEGA where you work. Brunelleschi's DUOMO can be seen via a semi-open window. Enter your COLLEAGUE, stage left, pursued by a bear. Upon closer glance, you see that the bear is not a bear, but instead a shimmering beta distribution of indeterminate shape and size. YOU are enchanted.
YOU: I am enchanted! Tell me more about your beta distribution! What is it about?
YOUR COLLEAGUE: This beta distribution refers to the pizza example from previous paragraphs ago! I know not much yet, but my priors are that most people like pizza between 50 and 70 happiness points! Where 100 is maximum happiness!
YOU (meditatively): What in the world do you mean by "most people"...?
In this case, I would: (a) assume "most people" means "95% of people", (b) normalize my pizza happiness points down to a beta distribution-able scale (50 - 70 becoming 0.5 - 0.7), and, (c) numerically calculate, using a least squares errors-ish approach and scipy's optimization algorithms, the beta parameters, \(\alpha\) and \(\beta\), that yield the correct proportions along a beta's cumulative distribution function. That is, find the \(\alpha\) and \(\beta\) where Pr(X < 0.5) = 0.025 and Pr(X < 0.7) = 0.975. You can read more about the method here and solving it using scipy's optimize.fmin algorithm here. I did such a thing, and voila!
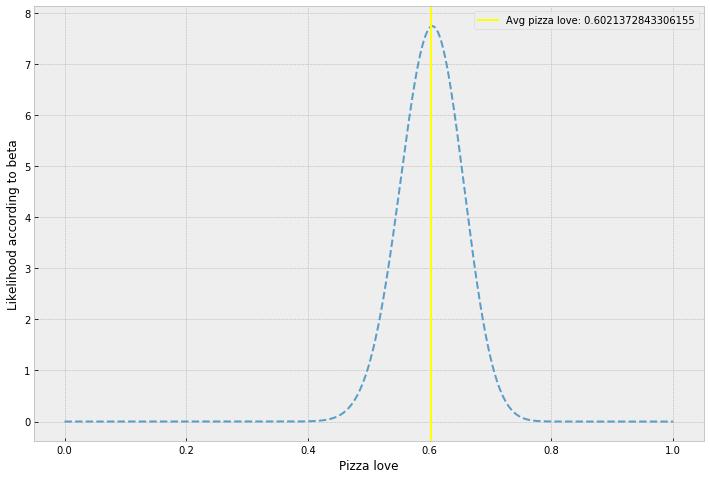
And now we can do descriptive stats of this crazy ol' prior we just confabulated out of the air!
SCENE 2. The BOTTEGA at night. You are manually debugging a NEURAL NETWORK using a power tool that emits sparks. A 3D PRINTER is printing Brunelleschi's DOME onto plastic.
YOUR COLLEAGUE (entering suddenly): Do you have it?! Do you have the numbers!
YOU: I do. (raising paper triumphantly) Our prior belief about the average, by the power of the
incantation, is that it's approximately 0.602137284331 -
YOUR COLLEAGUE: Hermahgerrddd STAHP. Don't use droning floating point precision to imply accuracy! It doesn't even matter, too. Since we'll be updating that with actual data soon, it'll become irrelevant.
YOU: So true. Long live the posterior!
YOUR COLLEAGUE: Long may it reign.
Reading
- Stats StackExchange: Help me understand Bayesian prior and posterior distributions
- Stats StackExchange: Do two quantiles of a beta distribution determine its parameters?
- John Cook: Parameters and percentiles
- John Cook: Finding Probability Distribution Parameters from Percentiles
- Hexing the technical interview - related to this post in style, not content; v wonderful